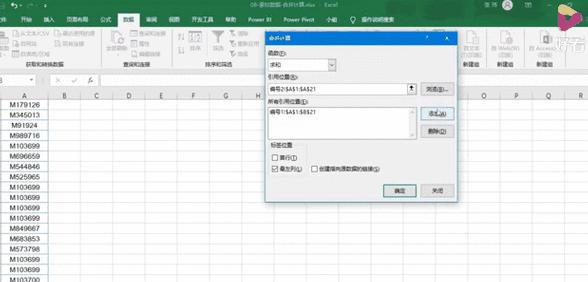
如何解决Oracle数据库中重复数据的方法步骤
在日常开发中,我们经常在数据表上遇到重复的数据,因此如何解决它们? 在这里,我们介绍了两种情况下数据奉献的方法:1 1 重复数据的完全定义的方法以推断表中的完全重复数据,可以使用以下SQL语句。可编写的“ #temp”为(从表名称中selectionOnonIdisinct*); - 创建临时表,并在特殊deduplica之后输入数据;此临时表; 然后清洁原始表的数据; 2 一些数据reduplicis首先,请求重复数据。
如果要删除这些重复的数据,则可以使用以下语句删除:从Awere表字段1 ,字段2 in的名称中删除:从groupby field 1 表,counting(*)从“ groupby field 1 ”表中计数(*),字段2 具有数字(*)> 1 )上述语句非常简单,可以删除数据。
但是,这种类型的删除执行效率非常低,并且对于大量数据,它可以使数据库握把。
基于上述情况,问题复制数据可以首先输入临时表,然后删除。
如下:可创建的临时表,例如(选择字段1 ,字段2 ,count(*),来自groupby字段1 ,具有计数(*)> 1 )的字段2 是删除操作:删除操作:删除从Awre Field 1 表,字段2 ,字段2 ,field 2 中的字段2 删除); 以上语句将删除所有副本。
以下是问题重复数据的示例:selecta.rowid,a。
=(selectmax(b.rowid),来自表Bwherea的名称。
字段1 = B.Field 1 anda.Field 2 = B.Field 2 = B.Field 2 )上述括号中的语句是请在重复数据中要求具有最大行的记录。
在外面,除了最大ROWID之外,我们还会查找其他重复数据。
因此,我们要删除重复数据并仅保留最新数据,因此我们可以这样写:用awherea.rowid表的名称擦拭! =(selectmax(b.Rowid)按名称。
临时创建的asselecta表。
oracle查询出来的数据如何消除重复数据
消除Oracle重复数据的特定步骤如下:1 首先,我们在表中检查重复数据。2 然后,我使用明确删除的功能来请求并删除数据重复。
3 然后,我们创建一个新表,然后将数据的远程重复插入新表中。
4 最后,使用截断清洁源表中的数据。
5 然后将重复的数据插入起始表中的新表中,以实现分解数据的效果。
oracle如何删除重复数据oracle如何删除重复数据只保留一条
数据可能是多种方法来删除Oracle数据库中数据数据库的方法。第一个在时间表中的某些字段中是相同的。
Oracle数据库DEDUPPLIET技术是以下优势和更好的备份数据,首先删除字段中的一些decation数据。
让我们谈谈如何首先找到重复的重复。
可以找到以下语句复制哪些数据。
字段1 ,字段2 ,计数(*)选择(*)选择(*)比第一个揭示(*)更有效的表(*)。
此时出发。
“是对的?” 使用SQL语句。
如何在Oracle数据库中的公共数据库中找到副本? 尝试以下操作:将名称更改为数据库的名称。
更改表名称的名称。
选择选择字段。
诺里名称名称名称(1 )我如何划分Oracle的语句? 你可以举个例子吗? 你可以举个例子吗? 给我一个例子。
例如,表Aname1 5 2 4 3 3 3 3 中有许多事实。
但是,未知名称应该寻找种子distinc(a.name)。
a.Idfromgrouperbya.name在开始时并询问许多框时,您需要与Groupby爬上来获得所需的结果。
如何决定文本副本副本的复制品? Oracle系统不会为图表Code_ref创建唯一的索引。
我们将在表中看到重复记录。
在创建唯一的索引之前,我们必须删除记录。
以下是在库表中确定相似记录的三种不同方法。
1 自我自我 查询方法。
Oracle系统具有用于ROWID表的奇怪列。
此列的最高(最大)或至少(min)功能使确定行行非常容易。
2 这是个好主意。
GroupBy方法由GroupBy /具有组函数的查询方法使用。
通过唯一的指标生长的列折叠,并通过计数每个组来计算每个组。
3 你是个好主意。
“ Orcapinto段落使用Alcolable命令来确定外部表的其他记录。
SQL脚本文件有些不同。
在NT系统下,脚本文件存储在Oracle_homeora8 1 dbmin目录中。
可以在数据库图表中很容易区分该表具有相同的记录,我该如何处理与情况相匹配的第一个项目? Oracle仅记录了与SQLServerrver编写和不同条件的情况相匹配的记录。
您必须使用关键字游泳。
如果 如果仅获得记录的记录,请选择列名。
如果要获得第一个记录,请从搜索名称中选择选择名称。
具体步骤如下: 首先,我们检查表中的下一个表。
2 这是个好主意。
然后,我使用了不同的去除功能来查找和删除重复项。
3 你是个好主意。
然后我们创建一个新表。
将可移动的重复信息输入新图表。
4 最后,使用后备箱清楚地清除原始表上的数据。
5 然后重复将数据添加到新表中,以实现深度耗尽数据的效果。
Oracle去除重复列的SQL语句怎么写
在Oracle数据库中,在查询结果中删除重复列是一个常见的要求。为此,可以使用单个关键字。
此关键字用于过滤Unreplica记录。
例如,以下示例显示了如何使用单独的关键字来删除所有列的重复值: 如果要仅删除某些列的重复值,则可以指定这些列,如下所示: selectDistinctname,在条件的情况下年龄;在上述查询中,单个关键字可确保名称和年龄列的总和是唯一的。
只要名称和年龄的总价值相同,即使其他列中的值相同,也被认为是重复的删除。
请注意,使用不同的关键字可以增加查询复杂性和执行时间,尤其是在涉及大量数据时。
因此,在实际应用中,您应该谨慎使用它,具体取决于您的特定需求。
此外,可以与Orderby结合使用不同的关键字来对结果进行排序。
示例:selectDistinctname,fromtable fromtable,在状态下订购,这将首先删除重复的名称和年龄组合,然后按名称和年龄进行排序。
编写查询时,请确保您了解单个关键字的工作方式,并根据您的特定需求选择适当的使用方式。
这对于提高查询的效率和准确性很重要。
Oracle 如何查找并删除重复记录
在Oracle数据库中查找和删除重复记录的方法主要包括使用汇总功能与子查询合作或加入查询,使用分析函数,并通过子Queries中的分析函数实现删除。这些方法在下面详细描述。
首先,创建样本表人并使用一些重复记录生成数据。
使用聚合功能查找单个字段的重复记录,例如为电子邮件字段寻找重复数据。
可以通过将统计信息和行返回的组分组大于1 来实现。
要查看完整的重复数据,使用子查询或连接查询。
要根据多个字段查找重复记录,您可以根据名称和电子邮件字段对统计信息进行分组,并同时找到具有相同名称和电子邮件的重复数据。
使用分析功能来提高性能和可读性。
使用Count()分析功能来找出现场重复的数量并保留原始表数据以避免辅助扫描。
仅返回记录超过1 次。
删除重复记录时,通常需要保留其中一个数据。
使用子查询匹配逻辑条件,例如保留最大的ID或最小的ID以删除其他重复记录。
您还可以使用诸如row_number()之类的分析函数对数据进行分组,并为每个数据分配一个唯一的数字,然后删除以大于1 的数字删除重复数据。
等级()或dense_rank()函数也适用于此函数。
总而言之,通过上述方法,您可以有效地查找和删除Oracle数据库中的单个字段和多个字段的重复数据,包括重复的记录。
删除重复数据时,您应该注意保留其中一个记录,并考虑添加独特的约束,以防止重复的数据再次生成。